

{kind=link}
Upcoming generative AI trends and Qualcomm Technologies’ role in enabling the next wave of innovation on-device
The generative artificial intelligence (AI) era has begun. Generative AI innovations continue at a rapid pace and are being woven into our daily lives to offer enhanced experiences, improved productivity and new forms of entertainment. So, what comes next? This blog post explores upcoming trends in generative AI, advancements that are enabling generative AI at the edge and a path to humanoid robots. We’ll also illustrate how Qualcomm Technologies’ end-to-end system philosophy is at the forefront of enabling this next wave of innovation on-device.
Upcoming trends and why on-device AI is key
dimensions.
Transformers, with their ability to scale, have become the de facto architecture for generative AI. An ongoing trend is transformers extending to more modalities, moving beyond text and language to enable new capabilities. We’re seeing this trend in several areas, such as in automotive for multi-camera and light detection and ranging (LiDAR) alignment for bird’s-eye-view or in wireless communications where global position system (GPS), camera and millimeter wave (mmWave) radio frequency (RF) are combined using transformers to improve mmWave beam management.




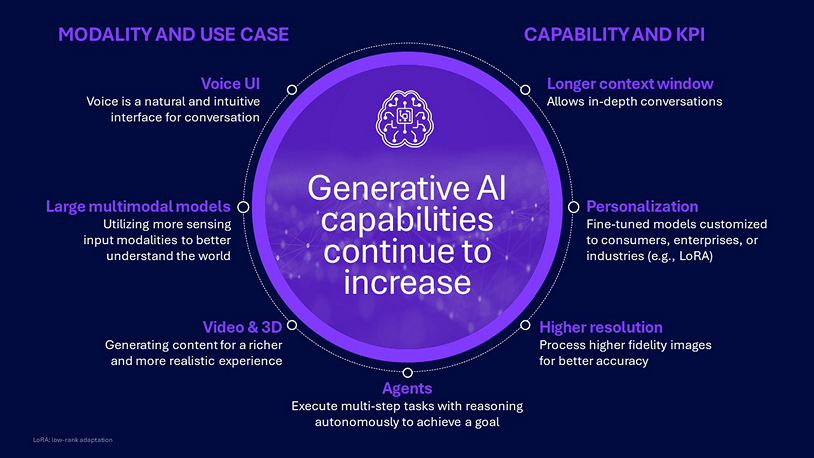
Another major trend is generative AI capabilities continuing to increase in two broad categories:
- Modality and use case
- Capability and key performance indicators (KPIs)
For modality and use cases, we see improvements in voice user interface (UI), large multimodal models (LMMs), agents and video/3D. For capabilities and KPIs, we see improvements for longer context window, personalization and higher resolution.
In order for generative AI to reach its full potential, bringing the capabilities of these trends to edge devices is essential for improved latency, pervasive interaction and enhanced privacy. As an example, enabling humanoid robots to interact with their environment and humans in real time requires on-device processing for immediacy and scalability.
Advancements in edge platforms for generative AI
How can we bring more generative AI capabilities to edge devices?
We are taking a holistic approach to advance edge platforms for generative AI through research across multiple vectors.
We aim to optimize generative AI models and efficiently run them on hardware through techniques such as distillation, quantization, speculative decoding, efficient image/video architectures and heterogeneous computing. These techniques can be complementary, which is why it is important to attack the model optimization and efficiency challenge from multiple angles.
Consider quantization for large language models (LLMs). LLMs are generally trained in floating-point 16 (FP16). We’d like to shrink an LLM for increased performance while maintaining accuracy. For example, reducing the FP16 model to 4-bit integer (INT4), reduces the model size by four times. That also reduces memory bandwidth, storage, latency and power consumption.
Quantization-aware training with knowledge distillation helps to achieve accurate 4-bit LLMs, but what if we need an even lower number of bits per value? Vector quantization (VQ) can help with this. VQ shrinks models while maintaining desired accuracy. Our VQ method achieves 3.125 bits per value at similar accuracy as INT4 uniform quantization, enabling even bigger models to fit within the dynamic random-access memory (DRAM) constraints of edge devices.
Another example is efficient video architecture. We are developing techniques to make generative video methods efficient for on-device AI. As an example, we optimized FAIRY, a video-to-video generative AI technique. In the first stage of FAIRY, states are extracted from anchor frames. In the second stage, video is edited across the remaining frames. Example optimizations include: cross-frame optimization, efficient instructPix2Pix and image/text guidance conditioning.
A path to humanoid robots
We have expanded our generative AI efforts to study LLMs and their associated use cases, and in particular the incorporation of vision and reasoning for large multimodal models (LMMs). Last year, we demonstrated a fitness coach demo at CVPR 2023, and recently investigated the ability of LMMs to reason across more complex visual problems. In the process, we achieved state-of-the-art results to infer object positions in the presence of motion and occlusion.
However, open-ended, asynchronous interaction with situated agents is an open challenge. Most solutions for LLMs right now have basic capabilities:
- Limited to turn-based interactions about offline documents or images.
- Limited to capturing momentary snapshots of reality in a Visual Question Answering-style (VQA) dialogue.
We’ve made progress with situated LMMs, where the model is able to process a live video stream in real time and dynamically interact with users. One key innovation was the end-to-end training for situated visual understanding — this will enable a path to humanoids.
More on-device generative AI technology advancements to come
Our end-to-end system philosophy is at the forefront of enabling this next wave of innovation for generative AI at edge. We continue to research and quickly bring new techniques and optimizations to commercial products. We look forward to seeing how AI ecosystem leverages these new capabilities to make AI ubiquitous and to provide enhanced experiences.

Senior Director of Technology,
Qualcomm Technologies
