
{kind=link}
AI is now the most significant workload in data centers and the cloud. It’s being embedded into other workloads, used for standalone deployments, and distributed across hybrid clouds and the edge. Many of the demanding AI workloads require hardware acceleration with a GPU. Today, AI is already transforming a variety of segments like finance, manufacturing, advertising, and healthcare. Many AI models are considered priceless intellectual property – companies spend millions of dollars building them, and the parameters and model weights are closely guarded secrets. Even knowing what some of the parameters are in a competitor’s model is valuable intelligence. Furthermore, the data sets used to train these models are also considered highly confidential and can create a competitive advantage. As a result, data and model owners are looking for ways to protect these, not just at rest and in transit, but in use as well.
Confidential Computing is an industry movement to protect sensitive data and code while in use by executing inside a hardware-hardened, attested Trusted Execution Environment (TEE) where code and data can be accessed only by authorized users and software. For AI workloads, this would include the model parameters, weights, and the training or inferencing data. Learn more about Confidential Computing at the Confidential Computing Consortium.
Attestation and Trust
Attestation is an essential process in Confidential Computing where a stakeholder is provided a cryptographic confirmation of the state of a Confidential Computing environment. It asserts that the TEE instantiated is genuine, conforms to their security policies, and is configured exactly as expected. The frequency of attestation is determined by policy and can happen at launch time and periodically during runtime of the TEE. Attestation is critical to establish trust in the computing platform you’re about to entrust with your highly sensitive data.
Intel and NVIDIA deliver Confidential Computing technologies that establish independent TEEs on the CPU and GPU, respectively. For a customer, this presents an attestation challenge, requiring attestation from two different services to gather the evidence needed to verify the trustworthiness of the CPU and GPU TEEs.
Through this collaboration, Intel and NVIDIA are providing a unified attestation solution for customers to verify the trustworthiness of the CPU and GPU TEEs for Confidential Computing based on Intel Xeon processors with Intel Trust Domain Extensions (Intel TDX) and NVIDIA Tensor Core H100 GPUs. Intel TDX is an architecture extension in the Intel Xeon family of processors that enables hardware-based TEEs. Intel TDX is designed to isolate VMs from the virtual machine manager (VMM)/hypervisor and any other software outside the Trust Domain, thus protecting the TD from a broad range of software attacks.
TEEs hosted on Intel processors can receive attestation services using several methods. The hosting Cloud Service Provider may offer an in-house attestation service, certain ISVs offer their own, or customers can build a private service. This article will focus on CPU attestation via Intel’s just-released cloud-based independent trust service, Intel Trust Authority. TEEs hosted on Nvidia GPU receive attestation via NVIDIA’s Remote Attestation Service (NRAS).
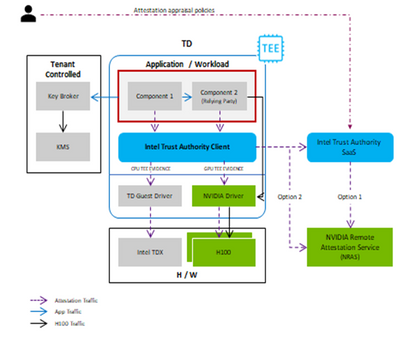
At the confidential computing summit, NVIDIA and Intel shared a unified attestation architecture, illustrated in the following figure.
- Intel Trust Authority Client collects evidence from the CPU and GPU TEEs and invokes the Intel Trust Authority SAAS for attestation verification.
- The Client includes workflows to gather GPU evidence via the NVIDIA driver, and to call NRAS either via the SaaS (Option 1) or directly (Option 2).
- Low-code: One call to collect and verify all attestation evidence.
- Minimal changes to applications to add Confidential Computing attestation.
Confidential Computing users will have two different options for attesting the CPUs and the GPUs as shown in the previous figure. Users either make separate calls to the Intel Trust Authority Client for full platform attestation and receive a single combined token or make separate calls to the Intel Trust Authority Client for CPU attestation and GPU attestation, receiving tokens for each. In both options, Intel Trust Authority SaaS verifies the CPU attestation evidence and NVIDIA NRAS verifies the GPU attestation evidence.
Intel Trust Authority: An independent trust service for CPU TEEs
Intel Trust Authority is an operator-independent, trustworthiness verification service delivered as a SaaS, and a client component referred to as the Intel Trust Authority Client. Intel Trust Authority provides comprehensive remote attestation capabilities starting with Intel CPU-based TEEs (Intel SGX and Intel TDX), with plans to support non-Intel CPU TEEs, GPU-based TEEs, and additional confidential computing devices as they become available. Intel Trust Authority provides the trustworthiness verification irrespective of where the TEEs are—public, private, or edge clouds. Intel Trust Authority is aligned to IETF-RATS architecture and supports both the passport model and background check model of attestation. Intel Trust Authority has a rich policy framework supporting very granular customer-defined appraisal policies for both CPU and GPU TEEs.
NVIDIA NRAS: Remote attestation service for NVIDIA GPU-based TEEs
The NVIDIA Remote Attestation Service (NRAS) is the SaaS service provided by NVIDIA for verifying the attestation reports of NVIDIA GPUs. NRAS capabilities include:
- Accept a GPU attestation report (evidence) as input from an attestor.
- Call the RIM service to fetch RIM Bundles (Golden Measurements) for comparison against the evidence.
- Call the NVIDIA OCSP service to validate the evidence signature and RIM signature.
- Compare the evidence against the certificate chain from the RIM bundle.
- Return attestation results as a signed Entity Attestation Token (EAT).
NRAS creates the signed EAT, based on a JSON Web Token (JWT). The Relying Party or users can call NRAS using the NVIDIA Attestation SDK or by calling the NRAS APIs directly.
In the rest of this blog, we walk through the next level of details of how this unified attestation works, with Intel TDX TEEs on the CPU and NVIDIA H100-based TEE on the GPU, and the workflows for each of the options with the Intel Trust Authority SaaS and NVIDIA NRAS. The key objective of this design is to encapsulate and simplify the work applications must do to incorporate attestation into their workflows. Applications simply make API calls into the Intel Trust Authority Client—such as collectCPUToken(), collectGPUToken(), or collectCompositeToken()—to trigger the attestation flows. All the complexity of fetching the TEE evidence as a signed report from the TEE hardware, sending that evidence to the attestation services, and fetching the signed attestation tokens is done behind the scenes by the services behind the Intel Trust Authority Client APIs. In the case of collectCompositeToken(), the Intel Trust Authority attestation token will be a composite signed EAT token, with distinct individual CPU and GPU attestation tokens contained in it.
Intel Trust Authority Client
The Intel Trust Authority Client is an essential component of Intel Trust Authority services, which encapsulates and abstracts the workflow required to gather the attestation evidence from the TEEs and securely deliver to the Intel Trust Authority SaaS, prior to launching workloads inside any TEE. The Trust Authority Client has a very extensible model and is integral to building Confidential Computing solutions. The Intel Trust Authority Client initiates attestation and can fetch the attestation both from the CPU and the GPU, and the signed token and certificates from the remote attestation services, including from Intel Trust Authority SaaS and NVIDIA NRAS.
For NVIDIA H100 GPU attestation, we provide two options for integrating the Intel Trust Authority Client and SaaS with NVIDIA NRAS for the GPU attestation.
Option 1: (Intel Trust Authority Client → SaaS → NRAS)
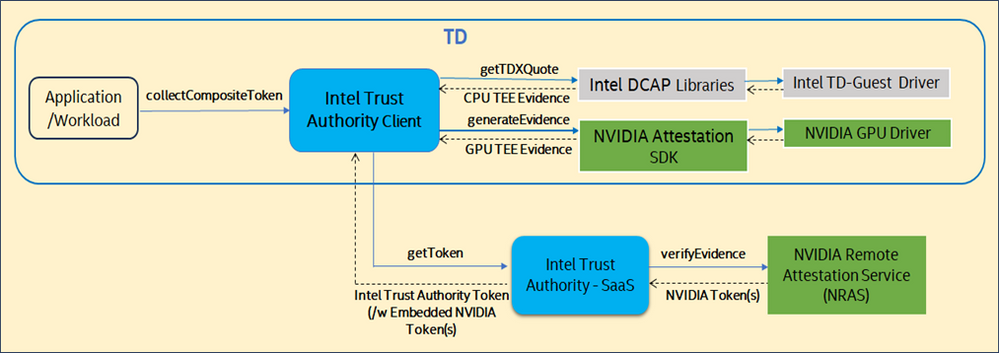
The following figure shows the higher-level flow for Option 1.
In this option, the Intel Trust Authority Client collects the attestation evidence from Intel TDX and H100 GPU and calls the Intel Trust Authority SaaS, which in turn calls out to NRAS to get the NVIDIA signed token with the verified evidence.
- Application invokes the collectCompositeToken() API in the Intel Trust Authority Client.
- The Intel Trust Authority Client gets a signed nonce from the Intel Trust Authority SaaS.
- The Intel Trust Authority Client requests the attestation report from the NVIDIA GPU driver in the CPU TEE (i.e., Intel TDX CVM) using the NVIDIA Attestation SDK with the nonce.
- The Intel Trust Authority Client receives the attestation evidence from the GPU driver.
(* The nonce generated by Intel Trust Authority is passed to the GPU driver for the SPDM measurement request to the GPU.) - The Client calls the SaaS to request the signed EAT token passing the GPU attestation evidence, and any attestation policy for the GPUs. The GPU attestation policy may also be pre-defined in the SaaS by the application owner.
- The Intel Trust Authority SaaS calls out to NRAS using the NVIDIA SDK, sending the evidence for verification, and collects the NVIDIA signed token from NRAS.
- The Intel Trust Authority SaaS verifies the NVIDIA token(s) and generates a composite Intel Trust Authority signed Token with embedded NVIDIA token(s) to the Intel Trust Authority Client.
- The Relying Party can get the signed token and the token signing certificate from the Intel Trust Authority SaaS and verifies the token with the certificate.
Option 2: (Intel Trust Authority Client → NRAS)
The following figure shows the higher-level flow for Option 2.
In this option, the Intel Trust Authority Client directly calls NRAS for GPU attestation, without calling into the Intel Trust Authority SaaS for attestation of the GPU TEEs. The remote attestation of the H100 GPU TEEs is performed directly by NRAS, without the Intel Trust Authority SaaS as an intermediary.
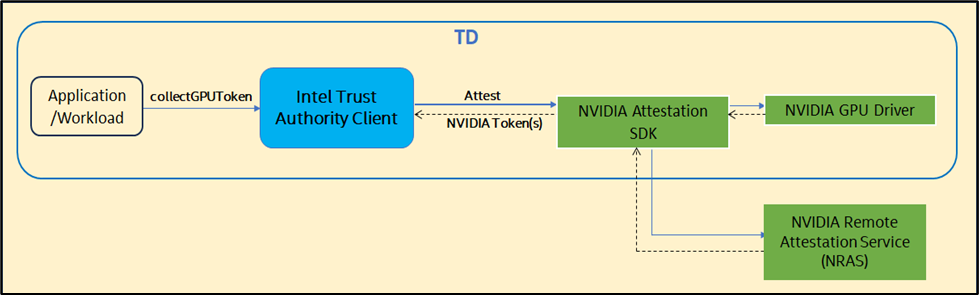
- Application invokes the collectGPUToken() API in the Intel Trust Authority Client.
- The Intel Trust Authority Client gets a signed nonce from the SaaS.
- The Intel Trust Authority Client requests the attestation report to the NVIDIA GPU driver in the CPU TEE (i.e., Intel TDX CVM) using the NVIDIA Attestation SDK with the nonce.
- The Intel Trust Authority Client receives the attestation evidence from the GPU driver.
- The Intel Trust Authority Client calls out to NRAS using the NVIDIA SDK which sends the evidence for verification and collects the NVIDIA signed token from NRAS.
- The Intel Trust Authority Client gets the token signing certificate from NRAS and verifies the token with the certificate.
We recommend Option 1 since it is the simplest—the user makes just a single API call to determine the safety of the environment. Option 2 is provided for users who prefer to manage each step themselves and who are willing to accept the higher complexity of that choice.
An example use case: Confidential training
Before any models are available for inferencing, they must be created and trained over a significant amount of data. For most scenarios, model training requires large amounts of computation, memory, and storage. A cloud infrastructure is well suited for this, but requires strong security guarantees at rest, in transit, and in use. The following figure shows a reference architecture for confidential training.
- The TEEs include both the Intel TDX CPU TEEs and NVIDIA H100 GPU TEEs. The key broker and distribution services must process attestation reports for both the CPUs and GPUs, before they release the keys to the TEEs.
- The key broker services will release the model and data decryption keys directly into the Trust Domain (TD, which is the Intel TDX TEE), once the attestation of the Intel TDX CPU and the attestation of the H100 GPU are both verified with Intel Trust Authority.
- If the key broker services do not release the decryption keys, the application will exit.
This architecture will ensure and provide proof to the model builder and the data owner that the model (parameters, weights, checkpoint data, etc.) and the training data aren’t visible outside the TEEs.

Sr. Principal Engineer and lead Security
Architect, CTO/Security Architecture and
Technology group
Intel Corporation