
{kind=link}
Artificial intelligence (AI) is having its big moment with the rise of generative AI models, but it often comes at an increasing cost: energy consumption and computing. To showcase how large models can be implemented more efficiently, Qualcomm Technologies, Inc. has recently presented the world’s first demo of Stable Diffusion running on an Android phone. However, research in the field of energy efficiency for AI is on-going. Taking the next step towards energy-efficient, on-device AI, Qualcomm is looking at new forms of compilers which can improve model performance.
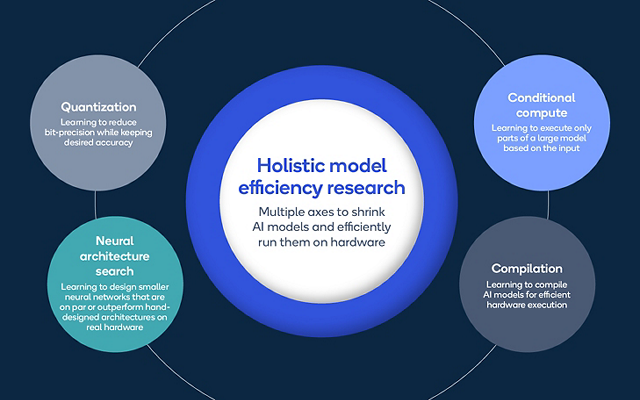
Power and thermal efficiency are essential for implementing AI models on smaller and smaller devices, but the challenge becomes more complex as the amount of AI models has been growing along several factors, including AI model type, application domain, processor type and number of devices. The work of the Qualcomm AI Research team covers more areas of power efficiency, from quantization and conditional compute to neural architecture search and compilation. Below, we will focus on our AI compiler work for efficient hardware execution.
Advanced Compilation Technology for the AI Stack
AI models are energy hungry and growing fast. For this reason, learning to compile AI models for efficient hardware execution is crucial.
What do compilers need?
A compiler analyzes source code — typically text from a programmer, written in a particular programming language — and produces an executable program. When they were invented in the 20th century, their main job was to read the input program, understand its meaning, and produce an executable program that runs efficiently on a single processor and does what the input program specified.
Nowadays, AI programs (models) are expressed in an even higher-level form, as a graph of so-called layers (you may have heard of convolution layers, fully connected layers etc.). These layers are often themselves expressed in C or C++.
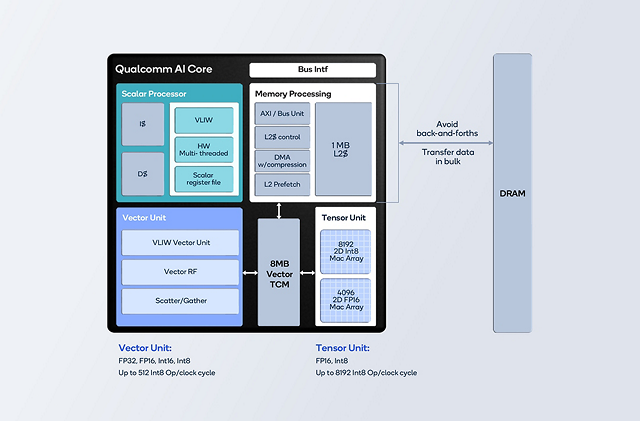
Computing platforms have evolved into hierarchies of parallel processing engines. We call these processing elements (PEs). PEs share a limited power budget and as many as possible need to be kept busy at the same time, otherwise you might as well have fewer PEs. In other words, parallelism is required — operations that can be run simultaneously. However, the path from PEs to dynamic random-access memory (DRAM), which is where input data comes from, is relatively long and slow.
Optimization
To tackle this, architectures introduce local memory, which is on the chip and closer to the processing elements in limited amounts (due to cost constraints). When data is moved to local memory, we want all its uses to happen before it is evicted to make room for other data. This way, we avoid back-and-forth transfers between DRAM and the local memories. Data movement engines called DMAs also accelerate these data transfers when they can be done in bulk. In the program optimization jargon, avoiding back-and forth transfers and transferring data in bulk is called data locality.
Hence, a large part of the optimizing work is to increase the parallelism and data locality of the input program. This is all achieved by the Qualcomm Polyhedral Mapper, developed by our research team.
The Qualcomm Polyhedral Mapper
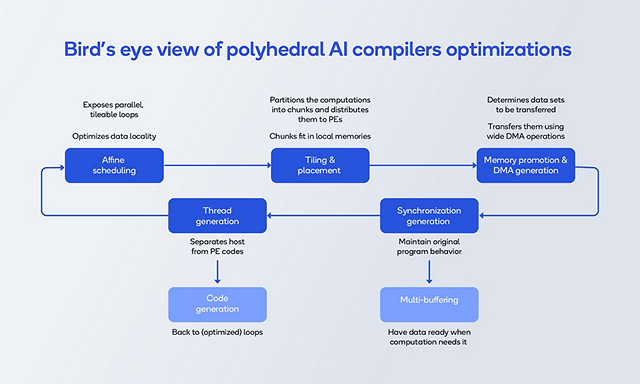
Polyhedral AI compiler optimization can be summarized as shown in Figure 3 below. We model the program as high-dimensional mathematical shapes called “polyhedra” and the optimization process is then a search for good choices of reshaping of the polyhedra to the PEs of the machine. This search can be done very fast using math solvers; optimization becomes solving certain equations fast. The abstraction of high-dimensional polyhedra is well-suited to the very deep loop nests that are implicit in modern ML models. These deep loop nests present many combinatorial choices for reshaping. We can solve for these choices using polyhedra and math solvers, much faster than other kinds of compilers.
We start with an “affine” scheduling transformation, which preconditions our loops for optimization, by finding and exposing independence between computations. This reshaping is finding different orientations of the computations to the machine. It simplifies the decomposition of loop computations into bigger packets named tiles. Then the decomposition step starts, where we optimize the shape and size of tiles for the targeted PEs and memory, after which we determine a distribution of tiles to PEs. Finally, we determine how data should be ordered in local memory and generate bulk transfers between remote and local memory. In addition, it’s important to detect when PEs need to wait for each other and insert just enough synchronization to make the parallel code correct. To prevent PEs from waiting for data to be transferred, data gets prefetched ahead of time using a technique called multi-buffering. This optimization process is performed hierarchically to fit the targeted hierarchy of PEs.
Finally, the code gets generated, first by separating the sequential code from the parallel code, then by converting the polyhedral representation back to loops.
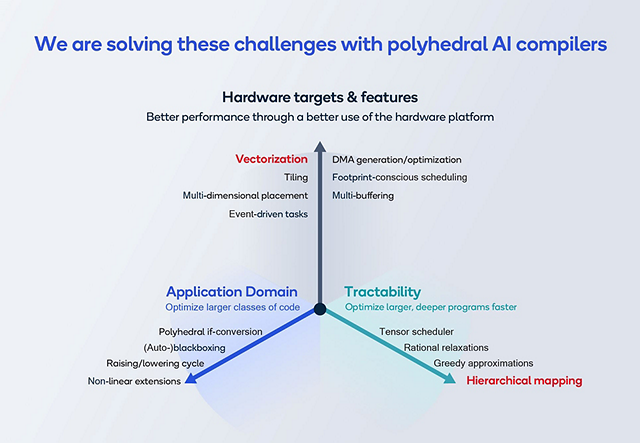
Even having met these challenges, AI compilers need to keep up with the growing variety of machine types, user applications, and size of AI models. Below, we are singling out two ways to achieve this by tackling the tractability (scalability) of compilers through hierarchical mapping and by tackling hardware targets/features through (auto-) vectorization.
Improving hierarchical mapping
To achieve better tractability of AI compilers, we developed the focalization method. This method allows the compiler to consider a set of tile dimensions independently of other dimensions.
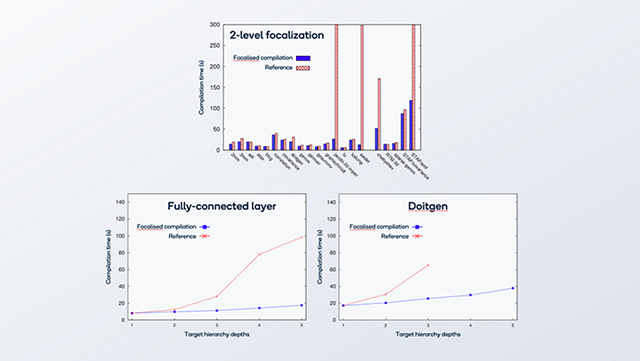
The effect of focalization can be significant for some loop codes. Let’s look at some results (Figure 4) where other tractability-helping techniques have been disabled. The effect is quite dramatic for some programs when targeting just two levels of hierarchy (2-level focalization), as you can see on the left-hand optimization time chart (lower is better).
The charts on the right-hand side in Figure 4 look at the time it takes to optimize a fully connected layer and a linear algebra kernel named doitgen as a function of the depth of the targeted machine (in terms of its levels of PEs).
On the fully connected layer, we see a reduction in the optimization time from ten times to two times. For doitgen, the optimization time goes above threshold after three levels, whereas the two-level focalization version scales well to five levels.
Improving automated vectorization
Next, we look at automated vectorization. Two underlying processes are key for this: the Qualcomm Polyhedral Mapper finds independent operations suitable for vectorization and its underlying compiler generates optimized calls to vector intrinsics.
Automatic optimization of a sequential code to three levels of parallelism (including vector) sped up the compile process 620 times and led to a third of the hand-tuned performance. That’s one third of the performance achieved quickly and with almost zero effort.
The Qualcomm Polyhedral Mapper can dramatically increase AI model developer productivity. By supporting more optimizations, we increase the performance and power efficiency of AI models running on Qualcomm platforms. By improving the tractability of these optimizations, we increase the performance of larger, more complex models.

Improved AI compilers are key to increased runtime and power efficiency as well as to making machine learning ubiquitous. Not only can we create more AI models more quickly, but we can also run them at high performance on power-constrained devices.
Toward the future of polyhedral AI compilers
In this blog post, I have presented only two of the many solutions we are working on for improving polyhedral AI compilers. With the iterative improvement of tractable compiler optimizations, as with hierarchical mapping and vectorization, the Qualcomm Polyhedral Mapper can achieve better overall compiler performance and productivity.

Principal Engineer, Qualcomm Technologies, Inc.